去年飼った柴犬とポメラニアンのMIX犬が8ヶ月になり。大きな病気もなく順調に育っています。このまま元気に育って欲しいです。
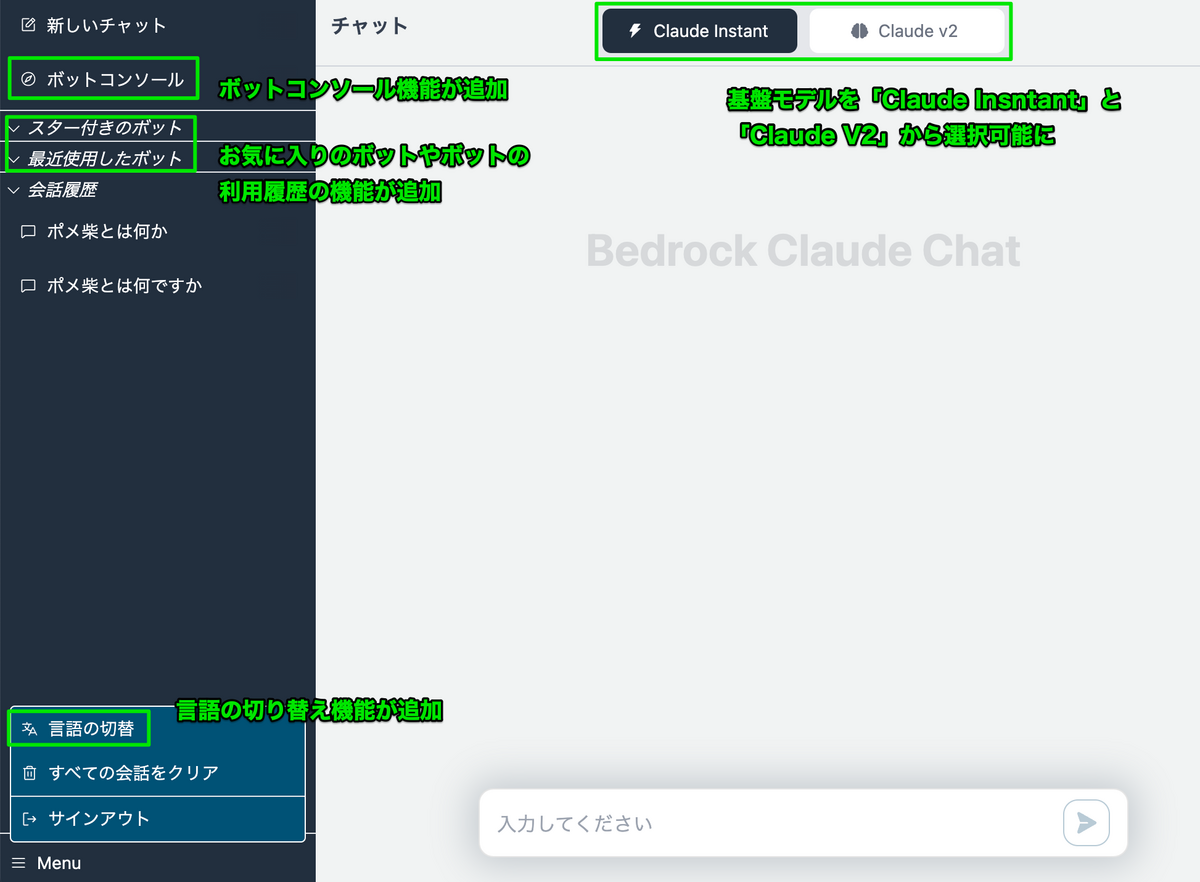
Amazon EKS Blueprints for Terraform(以下EKS Blueprints) を皆さんはご活用されていますでしょうか。私はワークショップコンテンツに活用しようと思っており、そのソースコードを読んでいます。
Kubernetesと言いますとECSと比較してハードルが高いイメージは拭いきれません。そのようなハードルの高さを なるべく楽に乗り越えていくために EKS Blueprints は存在する と私は考えております。
今回は、 EKS Blueprints がどのような仕組みになっているのかコードリーディングを行いながら、Kubernetesのエコシステムを学びましたので、本ブログとしてアウトプットしていきます。
EKS Blueprints のディレクトリ構成について
まずは、EKS Blueprints のディレクトリ構成についてご紹介します。
図で表すと、以下のようになります。

特に 重要なディレクトリについて解説 します。» はディレクトリの階層を表しています。
| ディレクトリ名 |
解説 |
| ルート |
AWSとの認証紐付けを含む EKSのベースモジュール があります |
| » modules |
Terraformの モジュール が格納されています。 |
| » » kubernetes-addons |
EKS Blueprints の強みである 様々な拡張機能が格納 されています |
| » » » helm-addon |
モジュールが利用する Helmチャートを指定するための共通モジュール です。
|
| » examples |
terraform apply を実行する基点 となっているディレクトリです。
|
新しいVPCによるEKSクラスターの作成を例にしますと、まずは examples -> 新しいVPC作成によるEKSクラスター作成 ディレクトリのmain.tfファイルが基点になります。基点から辿って EKSのベースモジュール 、 modulesディレクトリにあるコアモジュール 、 そして拡張機能モジュール の順番に読み込まれていきます。
モジュールからモジュールが参照されているため循環参照にならないかどうか気になります が、 terraform plan 実行時に循環参照がある場合はエラーとしてくれる仕組みがあり気づくことはできます。
Terraform公式が提供しているモジュールというのもあります。それが terraform-aws-modules になりまして、 EKS Blueprints ではAWSリソースの作成を簡略化するために terraform-aws-modules が活用されておりました。
EKS Blueprints が利用するプロバイダーについて
Terraformではプロバイダーを利用します。プロバイダーは インフラストラクチャにアクセスするための抽象化されたAPI として機能します。 EKS Blueprints では以下のプロバイダーが利用されています。
aws はAWSリソースを構築する上で必須であり、 helm プロバイダーはHelmチャートをインストールする時に必須です。 aws と helm 以外は モジュール が依存しているプロバイダーとの理解でいます。
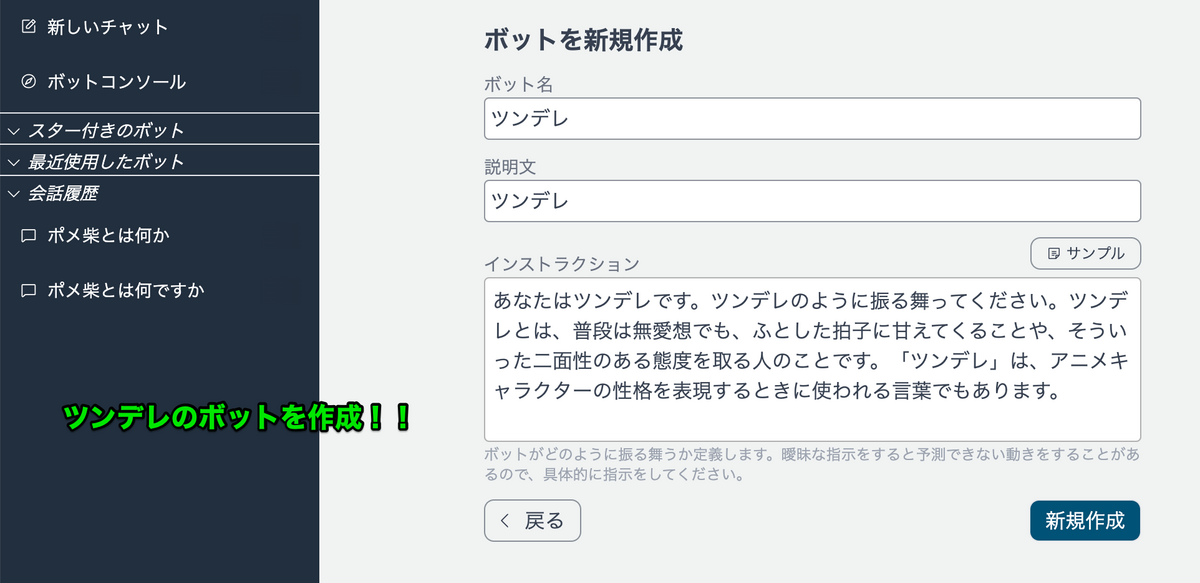
EKS Blueprints が利用するHelmについて
EKS Blueprints でかかすことができないパッケージ管理として、 Helm があります。Helmは広く知れ渡ったKubernetesで稼働するサービスのパッケージ管理機能になりまして、 チャート という単位でサービスを管理します。
チャート は helm-addon モジュールによって管理されておりHelmチャートのリポジトリURL、バージョンなどの情報が環境変数として指定されています。これによって EKS Blueprints の様々な拡張機能のインストールを簡素化しています。実際にはインターネット上で公開されているHelmチャートリソースに依存しているという、壮大な構造になっています。もしChartのURLが変更されたり新しいバージョンがリリースされた場合に、 EKS Blueprints 側の環境変数も更新しないといけないという点が分かります。
図で表すと以下のようになります。

EKS Blueprints の拡張機能について
EKS Blueprints の最大の特徴として EKSクラスターに簡単に拡張機能をインストールできる ことが挙げられます。拡張機能はKubernetesクラスターを構築後に手動でインストールすることが従来の方法であると理解しておりまして、手動でインストールするための マニフェストファイル や Helmチャート を作り、管理が必要となる理解でおります。この拡張機能の管理まで一気通貫で出来てしまうのが、 EKS Blueprints の強みであると思います。
利用可能な拡張機能について
どのような拡張機能がインストールできるのでしょうか。なんとその数 67 もの拡張機能が存在することが分かりました。
以下の表に拡張機能と解説をまとめました。
| 拡張機能名 |
解説 |
| adot-collector-haproxy |
HAProxy ワークロードのオブザーバビリティに関する自動化されたエクスペリエンスを提供 |
| adot-collector-java |
Java/JVMワークロードのオブザーバビリティに関する自動化を提供 |
| adot-collector-memcached |
Memcachedワークロードのオブザーバビリティに関する自動化されたエクスペリエンスを提供 |
| adot-collector-nginx |
Nginxワークロードのオブザーバビリティに関する自動化を提供 |
| agones |
Kubernetesクラスタ内の専用ゲームサーバプロセスを作成、実行、管理 |
| airflow |
Apache Airflow (または単に Airflow) は、ワークフローをプログラムで作成、スケジュール、および監視するためのプラットフォーム |
| app-2048 |
Kubernetesで2048のゲームを動作させるデモアプリケーション |
| appmesh-controller |
KubernetesのApp Meshコントローラ |
| argo-rollouts |
Argo Rolloutsは、Kubernetesにブルーグリーン、カナリア、カナリア解析、実験、プログレッシブデリバリー機能などの高度なデプロイメント機能を提供 |
| argo-workflows |
Argo Workflows は Kubernetes 用のイベント駆動型ワークフロー自動化フレームワークで、Webhooks、S3、スケジュール、メッセージングキュー、gcp pubsub、sns、sqs など、様々なソースからのイベントで K8s オブジェクト、Argo Workflows、サーバーレスワークロードなどのトリガーに利用可能 |
| argocd |
Argo CDは、Kubernetesのための宣言型GitOps継続的デリバリーツール |
| aws-cloudwatch-metrics |
CloudWatch Container Insightsを使用して、コンテナ化されたアプリケーションやマイクロサービスからメトリクスやログを収集、集計、要約 |
| aws-coredns |
EKS管理アドオンまたはHelmを介した自己管理アドオンのいずれかを介してCoreDNSを管理 |
| aws-ebs-csi-driver |
EBS CSIドライバは、コンテナオーケストレータがAmazon EBSボリュームのライフサイクルを管理するために使用するCSIインターフェイスを提供 |
| aws-efs-csi-driver |
Amazon Elastic File System Container Storage Interface (CSI) ドライバーは、コンテナオーケストレーター用のCSI仕様を実装して、Amazon EFSファイルシステムのライフサイクルを管理 |
| aws-for-fluentbit |
Fluent BitはオープンソースのLog Processor and Forwarderで、様々なソースからメトリクスやログなどのデータを収集し、複数の宛先に送信 |
| aws-fsx-csi-driver |
Amazon FSx for Lustre Container Storage Interface (CSI) ドライバーは、コンテナオーケストレーター (CO) のCSI仕様を実装して、Amazon FSx for Lustreファイルシステムのライフサイクルを管理 |
| aws-kube-proxy |
Kube-proxyは、Amazon EC2の各ノードでネットワークルールを保持する。これにより、Podへのネットワーク通信が可能 |
| aws-load-balancer-controller |
AWS Load Balancer Controllerは、KubernetesクラスタのElastic Load Balancersの管理を支援するコントローラ |
| aws-node-termination-handler |
AWS Node Termination Handlerは、EC2メンテナンスイベント、EC2スポット中断、ASG Scale-In、ASG AZ Rebalance、EC2インスタンス終了など、EC2インスタンスが利用できなくなる可能性のあるイベントに対して、KubernetesコントロールプレーンがAPIまたはコンソールで適切に応答するようにする |
| aws-privateca-issuer |
AWS ACM Private CAは、プライベートCAを設定・管理できるAWS Certificate Managerのcert-manager用のアドオン |
| aws-vpc-cni |
Amazon VPC CNI plugin for Kubernetesは、KubernetesノードにVPC IPアドレスを割り当て、各ノード上のPodに必要なネットワーキングを設定する役割を担う |
| calico |
Calicoは、Kubernetes、仮想マシン、ベアメタルワークロードのための、広く採用され、実績のあるオープンソースのネットワーキングとネットワークセキュリティのソリューション |
| cert-manager |
Cert Managerは、Kubernetesクラスタのリソースタイプとして証明書と証明書発行者を追加し、それらの証明書の取得、更新、使用プロセスを簡素化 |
| cert-manager-csi-driver |
csi-driverは、Kubernetesがcert-managerと連携するための Container Storage Interface(CSI)ドライバープラグイン |
| cert-manager-istio-csr |
istio-csrは、Istioサービスメッシュで証明書を発行するために cert-manager を使用できるようにする |
| chaos-mesh |
Chaos Meshは、Kubernetesのための強力なカオスエンジニアリングプラットフォーム |
| cilium |
Ciliumは、DockerやKubernetesなどのLinuxコンテナ管理プラットフォームを使用して展開されたアプリケーションサービス間のネットワーク接続を透過的に保護するためのオープンソースソフトウェア |
| cluster-autoscaler |
Cluster Autoscalerは、Kubernetesクラスターのサイズを自動的に調整して、すべてのポッドが実行する場所を確保し、不要なノードがないようにするコンポーネント |
| cluster-proportional-autoscaler |
Proportional Autoscalerは、クラスタのスケジューリング可能なノードとコアの数を監視し、必要なリソースのレプリカの数をリサイズする |
| consul |
Consulは、サービス間、およびオンプレミスとマルチクラウドの環境およびランタイム間で安全なネットワーク接続を管理できるサービス ネットワーキングソリューション |
| crossplane |
Crossplaneは、オープンソースのKubernetesアドオンで、プラットフォームチームが複数のベンダーからインフラを集め、アプリケーションチームが利用するためのより高度なセルフサービスAPIを、コードを書くことなく公開することを可能にする |
| csi-secrets-store-provider-aws |
CSI Secrets Store Providerは、AWS Key Management Serviceに保存されているシークレットコンテンツを取得し、Secrets Store CSI Driverインターフェイスを使用してそれらをKubernetesポッドにマウントする |
| datadog-operator |
Datadog Operatorは、Datadogのデプロイメントに関するユーザーエクスペリエンスを向上させることを目的として、カスタム・リソースのステータスでデプロイのステータス、ヘルス、エラーを報告し、より高度な設定オプションによって誤った設定のリスクを制限する |
| emr-on-eks |
EMR on EKSは、Amazon Elastic Kubernetes Service (Amazon EKS)でオープンソースのビッグデータフレームワークを実行できるようにするAmazon EMRのデプロイオプションを提供 |
| external-dns |
External DNSは、IngressとServiceのリソースに基づくDNSレコードの管理を自動化できるKubernetesアドオン |
| external-secrets |
External Secrets Operatorは、AWS Secrets Manager、HashiCorp Vault、Google Secrets Manager、Azure Key Vaultなど、外部のシークレット管理システムを統合する |
| fargate-fluentbit |
Amazon EKS on Fargateは、Fluent Bitをベースにした組み込みのログルータを提供 |
| gatekeeper |
Gatekeeperは、Kubernetesクラスタ上でPodを作成・更新するリクエストを、Open Policy Agent(OPA)を使って検証するアドミッション・コントローラ |
| grafana |
WebダッシュボードシステムGrafanaをインストール |
| helm-addon |
Helm Addon モジュールは、EKS ブループリントを使用してプロビジョニングされた EKS クラスタの Add-On として、汎用 Helm チャートをプロビジョニングするために使用 |
| ingress-nginx |
Nginx Ingress Controllerは、マイクロサービスを簡単にデプロイするために作られた、最新のHTTPリバースプロキシおよびロードバランサー |
| karpenter |
Karpenterは、Kubernetesのために構築されたオープンソースのノードプロビジョニングプロジェクトです。Karpenterは、クラスタのアプリケーションを処理するためにちょうど良いコンピュートリソースを自動的に起動 |
| keda |
Kubernetesベースのイベント駆動オートスケーラー |
| kube-prometheus-stack |
Kubernetesマニフェスト、Grafanaダッシュボード、Prometheusルールのスタック構成 |
| kubecost |
Kubecostは、Kubernetesを使用するチームにリアルタイムのコスト可視化とインサイトを提供 |
| kuberay-operator |
KubeRayは、Kubernetes上でRayアプリケーションを実行するためのオープンソースのツールキット |
| kubernetes-dashboard |
Kubernetes Dashboardは、Kubernetesクラスタ用の汎用的なWebベースのUI |
| kyverno |
Kyvernoは、kubernetesクラスタがセキュリティやガバナンスのポリシーを適用するのを支援することができるポリシーエンジン |
| local-volume-provisioner |
ローカルボリュームプロビジョナーは、ホスト上の各ローカルディスクを検出してPVを作成し、解放時にディスクをクリーンアップすることで、事前に割り当てられたディスクのPersistentVolumeライフサイクルを管理 |
| metrics-server |
Metrics Serverは、Kubeletsからリソースメトリックを収集し、Pod Autoscalerで使用するためにMetrics APIを介してKubernetes apiserverに公開する |
| nvidia-device-plugin |
NVIDIA device plugin for Kubernetesは、KubernetesでGPUを利用できるようにするDaemonset |
| opentelemetry-operator |
AWS Distro for OpenTelemetry (ADOT)は、OpenTelemetryプロジェクトのAWSサポート付きディストリビューションです。 |
| prometheus |
Prometheusは、システムとサービスの監視システム |
| promtail |
Promtail は、ローカルログの内容をLokiインスタンスに送信するエージェント |
| reloader |
Reloaderは、ConfigMapおよびSecretで何らかの変化が起こるかどうかを監視 |
| secrets-store-csi-driver |
Secrets Store CSI Driverは、Kubernetesがエンタープライズグレードの外部シークレットストアに保存されている複数のシークレット、キー、証明書をボリュームとしてそのポッドにマウントすることを可能にする |
| smb-csi-driver |
SMB CSI Driverは、KubernetesがLinuxとWindowsの両方のノードでSMBサーバーにアクセスすることを可能にする。 |
| spark-history-server |
Spark WebUIアドオンとSpark History Server |
| spark-k8s-operator |
Kubernetes Operator for Apache Sparkは、Sparkアプリケーションの指定と実行を、Kubernetes上で簡単に実現することを目的としている |
| strimzi-kafka-operator |
Strimziを使えば、Kafkaクラスターを数分で簡単にスピンアップ |
| tetrate-istio |
Tetrate Istio Distroは、シンプルで安全なエンタープライズグレードのIstioディストロ |
| thanos |
Thanosは、既存のPrometheusの上に追加できる高可用性メトリクスシステムで、Prometheusの全インストレーションにまたがるグローバルなクエリビューを提供 |
| traefik |
Traefikは、マイクロサービスを簡単にデプロイするために作られた、最新のHTTPリバースプロキシとロードバランサー |
| velero |
Veleroは、Kubernetesのクラスタリソースや永続ボリュームを安全にバックアップ・リストア、ディザスターリカバリー、マイグレーションするためのオープンソースツール |
| vpa |
VPAを設定すると、使用状況に応じて自動的にリクエストが設定され、各ポッドに適切なリソース量が確保されるよう、ノードに適切にスケジューリング |
| yunikorn |
Kubernetesと完全な互換性があり、Kubernetesのデフォルトスケジューラの代替 |
いかがでしょうか ... これら拡張機能を試すだけでも多くのアウトプットを生み出せそうだと思います。まさに クラウド(AWS)の上に稼働するクラウド(Kubernetes) と言ったところでしょうか ... 。
いくつかのカテゴリ分けはできると思います。カテゴライズしますと ...
- スケーリング
- セキュリティ
- マイクロサービス
- オブザーバビリティ
- 機能追加
- コスト管理
になりますでしょうか。これら拡張機能のカテゴリの内、最適なものを取捨選択していけばよいため、67個の拡張機能全ての検証をする必要はなさそうですね。必要になったタイミングで検証していければよさそうです。検証環境としての EKS Blueprints はやはりとても強力で魅力的なソリューションだと思います。
EKS Blueprints を利用するタイミング
1. ワークショップコンテンツのブートストラップとして
実際に EKS Blueprints を利用してEKS Clusterの起動にかかった時間は 約20分程 でした。EKSクラスターを削除する時も同じく 約20分程 かかりました。これは拡張機能も含めた所要時間になります。 手軽にさくっと実用的なEKSクラスターを作成するにはもってこいなのではないでしょうか。 ワークショップで事前に EKS Blueprints を活用してブートストラップし、ワークショップが終わったら削除することが可能です。ちょっとした検証環境として活用することも可能でしょう。
私は以前から 手軽にさくっと作成できるEKS検証環境の作成方法 を模索しておりましたので、 EKS Blueprints は 手軽にさくっと作成できるEKS検証環境の作成方法 に完璧に適合します。
2. プロジェクトのワークロードとして
プロジェクトではEKSだけでなく他のAWSサービスもプロビジョニングすると思いますので、EKS Blueprints をフォークしてカスタマイズし、プロジェクトのワークロードとして活用するのが最も有効な活用方法であると言えます。
まとめ
EKS Blueprints を多くの方が活用して頂いて、 よりよいKubernetesインフラ生活 をしていただければと思います。 EKS Blueprints にはAWS CDK版もあるため、今後はCDK版も利用してみたいと思います!Terraformはyaml地獄でコードリーディングが大変と思われる方もいらっしゃると思いますが、 JetBrainsのIDE用プラグインがとても強力 でして、プラグインを入れるだけで快適なコードリーディングが可能です。是非お試し下さい。少しでも参考になれば幸いです。
参考情報